Trajectory Optimization on Stoch 2
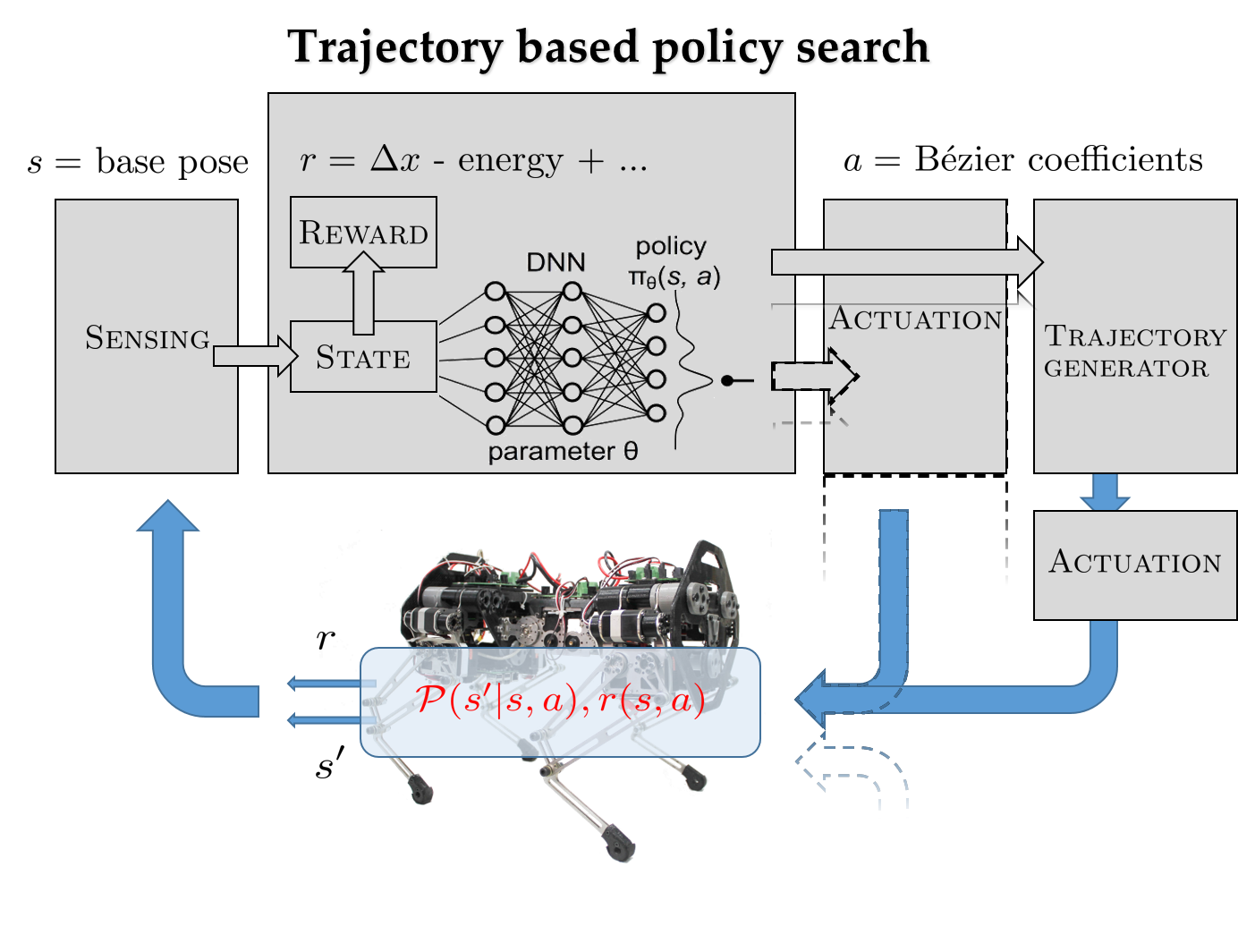
In this paper, we explore a specific form of deep reinforcement learning (D-RL) technique for quadrupedal walking—trajectory based policy search via deep policy networks. Existing approaches determine optimal policies for each time step, whereas we propose to determine an optimal policy for each walking step. We justify our approach based on the fact that animals including humans use “low” dimensional trajectories at the joint level to realize walking. We will construct these trajectories by using Bezier polynomials, with ´ the coefficients being determined by a parameterized policy. In order to maintain smoothness of the trajectories during step transitions, hybrid invariance conditions are also applied. The action is computed at the beginning of every step, and a linear PD control law is applied to track at the individual joints. After each step, reward is computed, which is then used to update the new policy parameters for the next step. After learning an optimal policy, i.e., an optimal walking gait for each step, we then successfully play them in a custom built quadruped robot, Stoch 2, thereby validating our approach.


Citation
@inproceedings{kolathaya2019trajectory,
title={Trajectory based deep policy search for quadrupedal walking},
author={Kolathaya, Shishir and Joglekar, Ashish and Shetty, Suhan and Dholakiya, Dhaivat and Sagi, Aditya and Bhattacharya, Shounak and Singla, Abhik and Bhatnagar, Shalabh and Ghosal, Ashitava and Amrutur, Bharadwaj and others},
booktitle={2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)},
pages={1--6},
year={2019},
organization={IEEE}
}
Related Papers
|
2019 October |
IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) 2019 New Delhi, India. |
People

Shishir Kolathaya

Ashish Joglekar
Abhimanyu


Shalabh Bhatnagar

Bharadwaj Amrutur
